
Tianhao Gao
- Algorithm Engineer, JD.com, 2022-now
- M.S. in Computer Technology, Peking University, 2019-2022
- B.S. in Software Engineering, Wuhan University of Technology, 2015-2019
Email: gaotianhao@pku.edu.cn
Publications
📚 Conference Papers
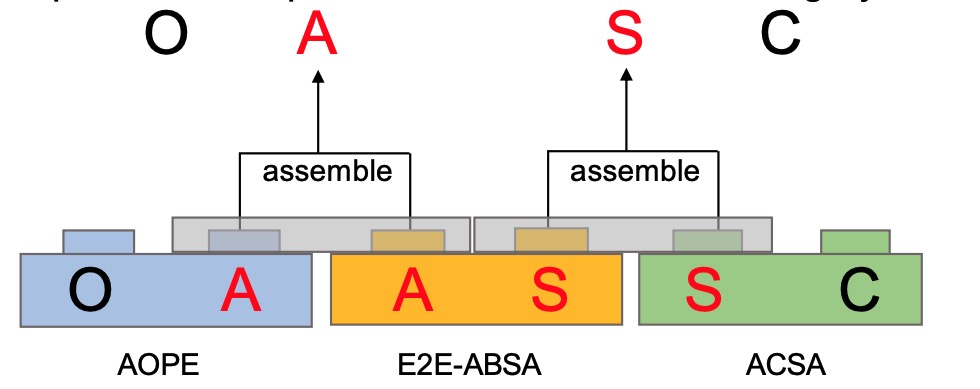
1. LEGO-ABSA: A Prompt-based Task Assemblable Unified Generative Framework for Multi-task Aspect-based Sentiment Analysis
Tianhao Gao, Jun Fang, Hanyu Liu, et al. (COLING 2022)
📄 Paper | 📽️ Slides | 📝 Introduction
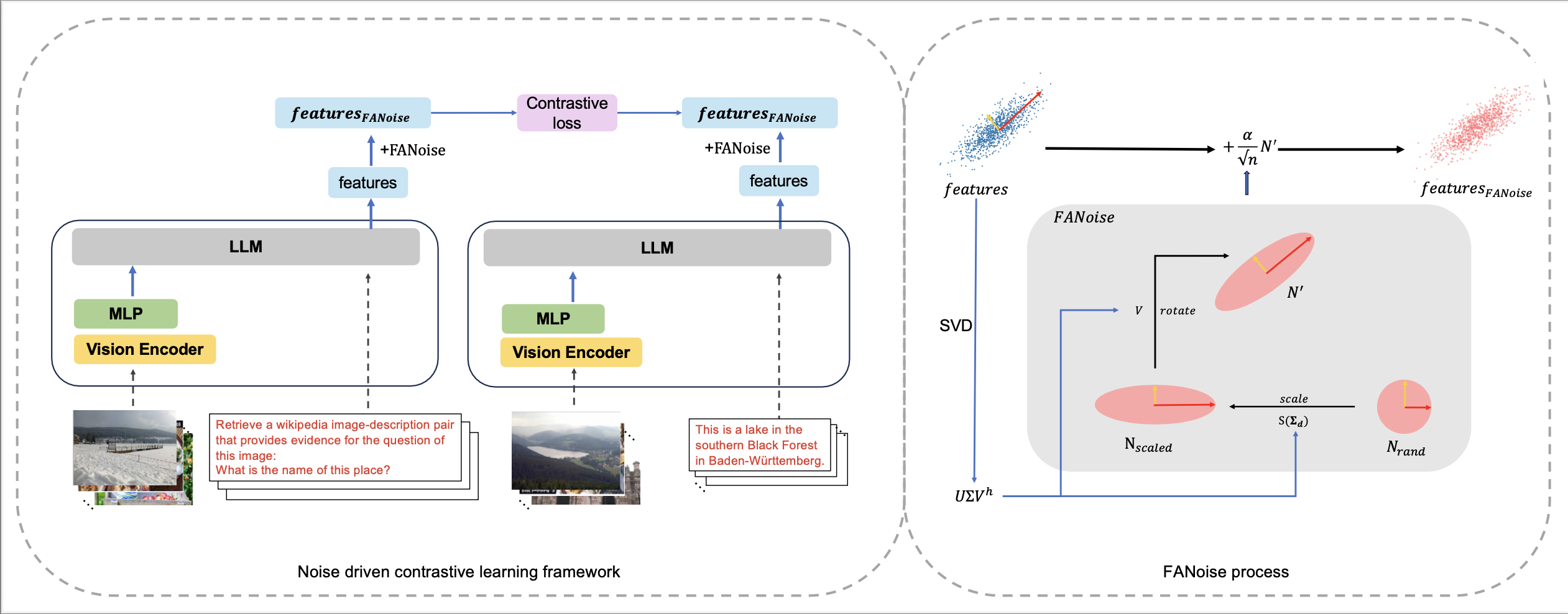
3. FANoise: Feature-Adaptive Noise Driven Representation Learning
Jiaoyang Li, Jun Fang, Tianhao Gao, et al. (AAAI 2026)
📄 Paper | 📝 Introduction
📑 Preprints
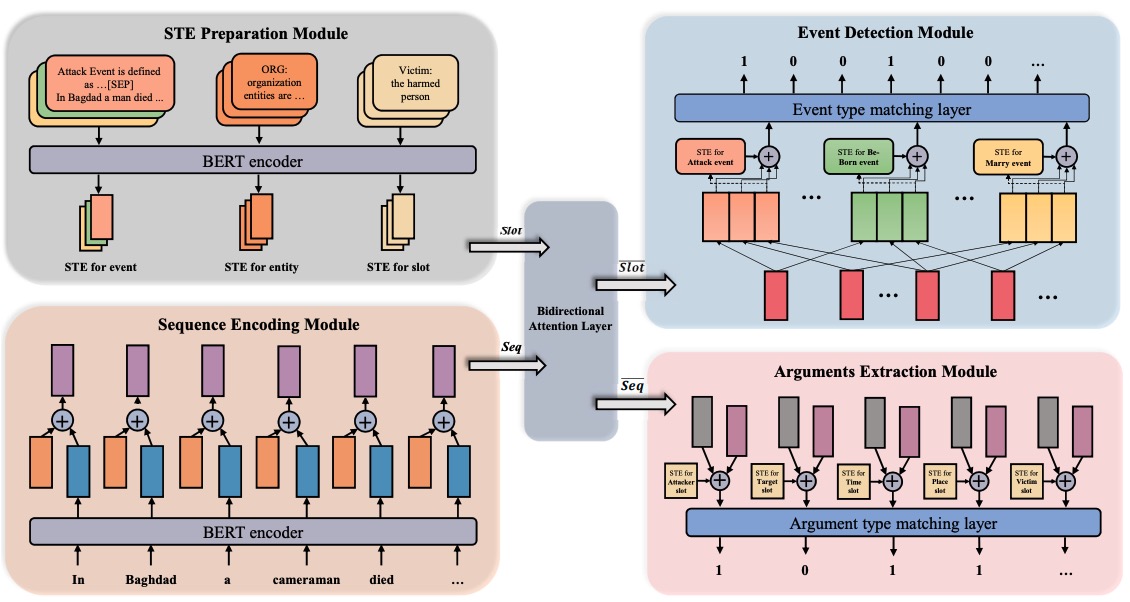
Joint Event Extraction via Structural Semantic Matching
Haochen Li, Tianhao Gao, Weiping Li, et al. *(Preprint, 2020)
📄 arXiv | 📝 Introduction
Patents
- Tianhao Gao, et al. “An Iterative Training Framework and Hierarchical Contrastive Loss for Graph-Text Matching” Submitted
- https://www.patentguru.com/cn/search?q=CN115759292A 《模型的训练方法及装置、语义识别方法及装置、电子设备》
🚀 Projects
📌 Project 1: 多模态商品内容标签打标系统
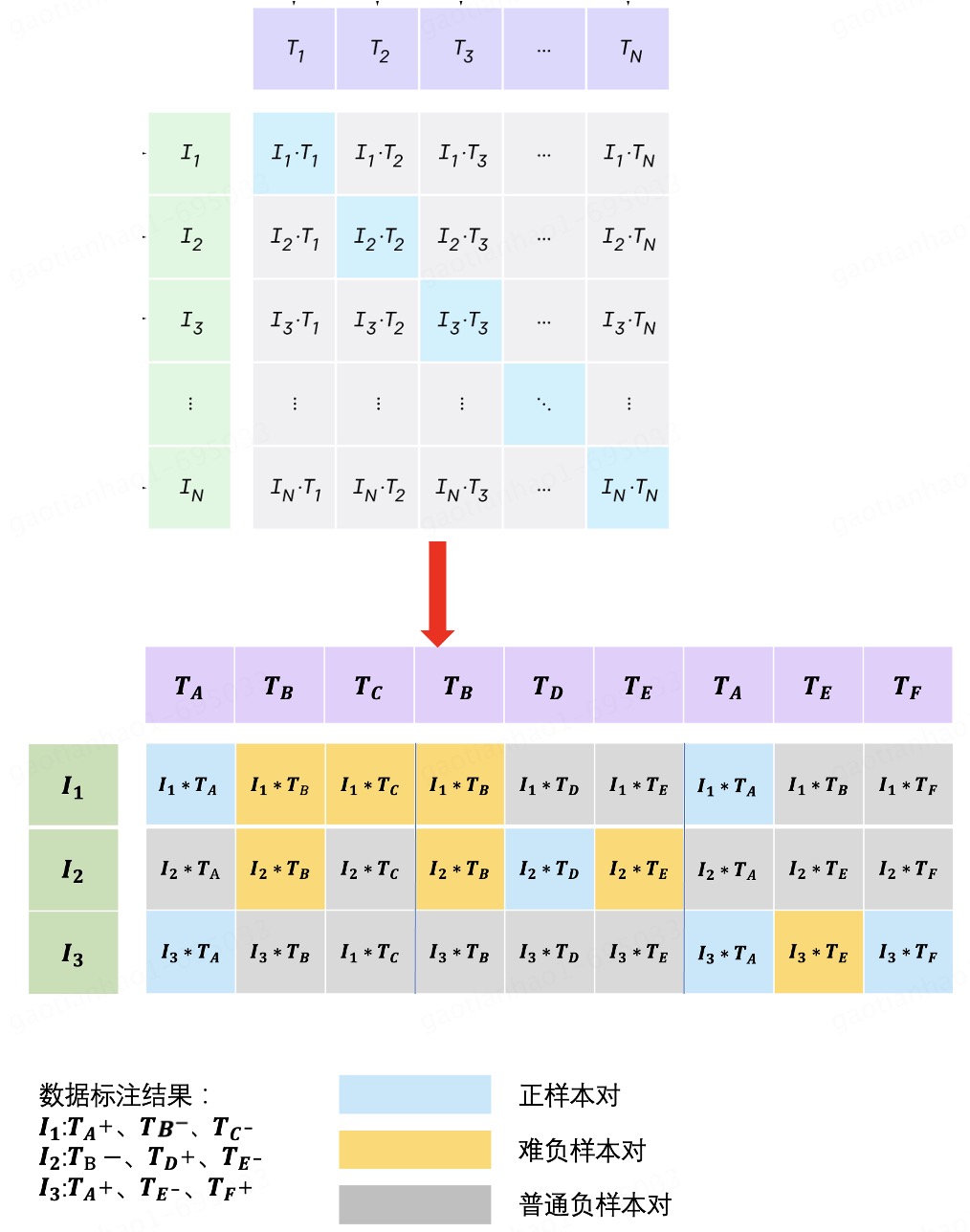
- 🔹 Selected the optimal base model and architecture through a thorough comparison and evaluation of different alternatives.
- 🔹 Constructed high-quality training data using PySpark and Hive SQL techniques.
- 🔹 Trained a multi-modal tagging model and developed a recursive algorithm to determine the appropriate threshold, achieving an impressive 90% accuracy.
📌 Project 2: 京东前台类目识别模型
(图片待添加)
- 🔹 内衣类目完成 Qwen2.5-7b 模型 SFT,业务验收准确率达到 90.5%。完成内衣类目全量数据刷数,沉淀 1.2亿 数据资产。AB 实验初步结果体验得分绝对提升 0.25分,符合业务预期。
- 🔹 前台类目识别完成模型迭代方案升级,升级后的方案不依赖人工数据标注,可自动化进行难例挖掘。
- 🔹 服饰一级类目产品词挖掘,基于 180天全量搜索 query,产出约 1万产品词。
📌 Project 3.1: 京东商详页问答 RAG 模型
(图片待添加)
- 🔹 基于 GPT-4 完成商详问答 SFT 数据集构建,并建立测试数据集。
- 🔹 构建问答增强的 Bloom 模型,并基于 LangChain 构建问答全流程,算法自测准确率 88%,完成三个一级类目服务部署上线。
- 🔹 调研 RAG 领域主流做法。利用商详问答 LLM 模型生产监督数据,反向优化向量检索模型,将向量检索模型的 top-1 准确率由 76.24% 提升至 77.29%,提升 1.1个百分点,将 bge-small 模型的能力提升至 stella-large 水平。
📌 Project 3.2: Apple 自营店客服 RAG
(图片待添加)
- 🔹 RAG 模块采用 GLM3 模型,自测准确率 85%+。全流程 UAT 测试中,严格正确率为 81.1%,加上部分正确率则为 89.5%。服务已上线,业务 AB 测试中。
- 🔹 RAG 模块 baseline 模型升级,完成 Qwen1.5 和 Qwen2 系列模型在 Apple 的训练和效果验证,迭代上线推进中。
- 🔹 基于 LLM + 客服对话,构建信息抽取 pipeline,完成客服有效对话抽取能力建设,并在 Apple Watch 品类完成测试。基于该能力可生产的数据包括:
- 客服有效对话数据
- 问答数据对(用于编码模型训练)
- 商品信息结构化图谱
- 🔹 构建 Mac 品类训练数据,完成 Apple 问答模型增量训练,通过回归测试,Mac 品类上线,准确率达到 85%+ 目标。
📌 Project 4: 商品理解大模型
(图片待添加)
- 🔹 商品理解大模型准确率达到 90%+。
- 🔹 沉淀数据资产新增总量 11.5亿,包括:
- 前台类目:5.7亿
- 商品数据资产:1.2亿
- 规格属性抽取:3.8亿
- 品类知识图谱:0.4亿
- 商品短标题:0.4亿
- 🔹 新增数据资产存储量超过 1TB。
📌 Project 5: 标签联想能力建设
(图片待添加,内容待完善)
📌 Project 6: Counterfeit Brand Titles Detection System
(图片待添加)
- 🔹 Performed a comprehensive problem analysis and proposed a modular system architecture to decouple and solve various challenges.
- 🔹 Employed traditional algorithms, including edit distance, minimum window substring, and recursive algorithms combined with the CV2 library for effective counterfeit detection.